Claude Sonnet 5: Anthropic's Agentic Leap at Half the Opus Price
.webp)
Every few months, an AI release changes what you can realistically build at a given budget. Claude Sonnet 5, launched by Anthropic on June 30, 2026, is one of those releases. For the first time, Sonnet-tier pricing buys you Opus-tier agentic depth: a model that does not just answer questions but plans tasks, runs tools, checks its own work, and finishes complex workflows without needing you to hold its hand at every step. For a startup in Bangalore, a product team in Lagos, or an engineering firm in São Paulo running AI on tight margins, that changes the calculation entirely.
The Gap It Closes
Sonnet 4.6 was a capable model for single-turn tasks: drafting, answering, summarizing, writing code for a function you described clearly. Where it struggled was in the kind of work that defines modern AI pipelines: tasks that require planning, using tools, reading results, and adapting. Ask it to investigate a bug, write a fix, test it, and verify the result, and it would often stall partway through, asking for clarification or producing output that needed significant human review before the next step.
Sonnet 5 was built specifically to close that gap. The model plans before it acts. It uses tools natively, including browsers and terminals, without requiring elaborate prompting to trigger that behavior. And it checks its own output without being told to: a step called self-verification that reduces the number of review rounds in agentic pipelines in practice, not just on paper.
What Is Actually New
The changes are not cosmetic. Here is what Sonnet 5 does differently from Sonnet 4.6, based on Anthropic's published capabilities and early tester feedback:
- Autonomous planning: lays out a task sequence before executing, rather than reacting step by step to each prompt
- Native tool use: browser, terminal, and file system access built into the agentic loop, not bolted on
- Self-verification: reviews its own output for correctness before returning it, without the user asking
- Multi-step completion: finishes complex workflows where Sonnet 4.6 would stop and request guidance
- Better resistance to prompt injection: the model is harder to manipulate when processing external content as part of a task
- Lower sycophancy: less likely to agree with incorrect premises or tell you what you want to hear
- Lower hallucination rate than Sonnet 4.6 on knowledge-heavy tasks
Early testers reported real pull requests carried through to a tested, verified result autonomously, bug investigations where Sonnet 5 wrote tests, implemented fixes, and verified them in a single pass, and CRM workflows completed end-to-end including data updates and outbound communications in one run.
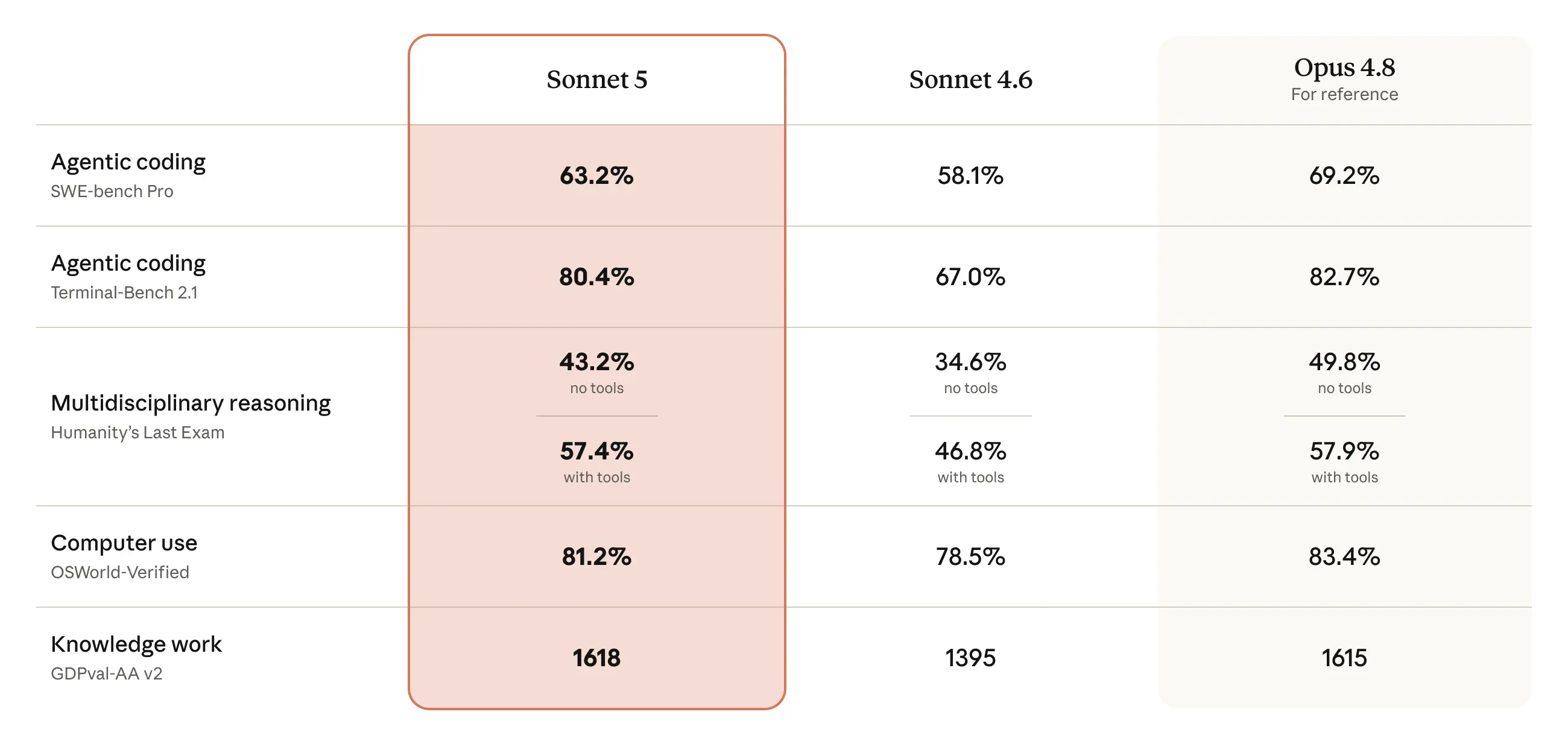
Benchmarks: Where It Stands
Anthropic published results on two evaluations designed for agentic capability. Static knowledge tests like MMLU are less relevant when the question is "can this model do my work." These two are closer to that question.
On BrowseComp, which tests agentic web research across multiple pages, Sonnet 5 offers a wider cost-to-performance range than Sonnet 4.6. You can get more done per dollar. On OSWorld-Verified, which tests the model's ability to interact with real desktop interfaces including applications and operating systems, Sonnet 5 matches Opus 4.8 scores at specific effort settings. That is the headline number: Sonnet 5 at certain configurations performs like Opus 4.8 on computer use, at a fraction of the price.
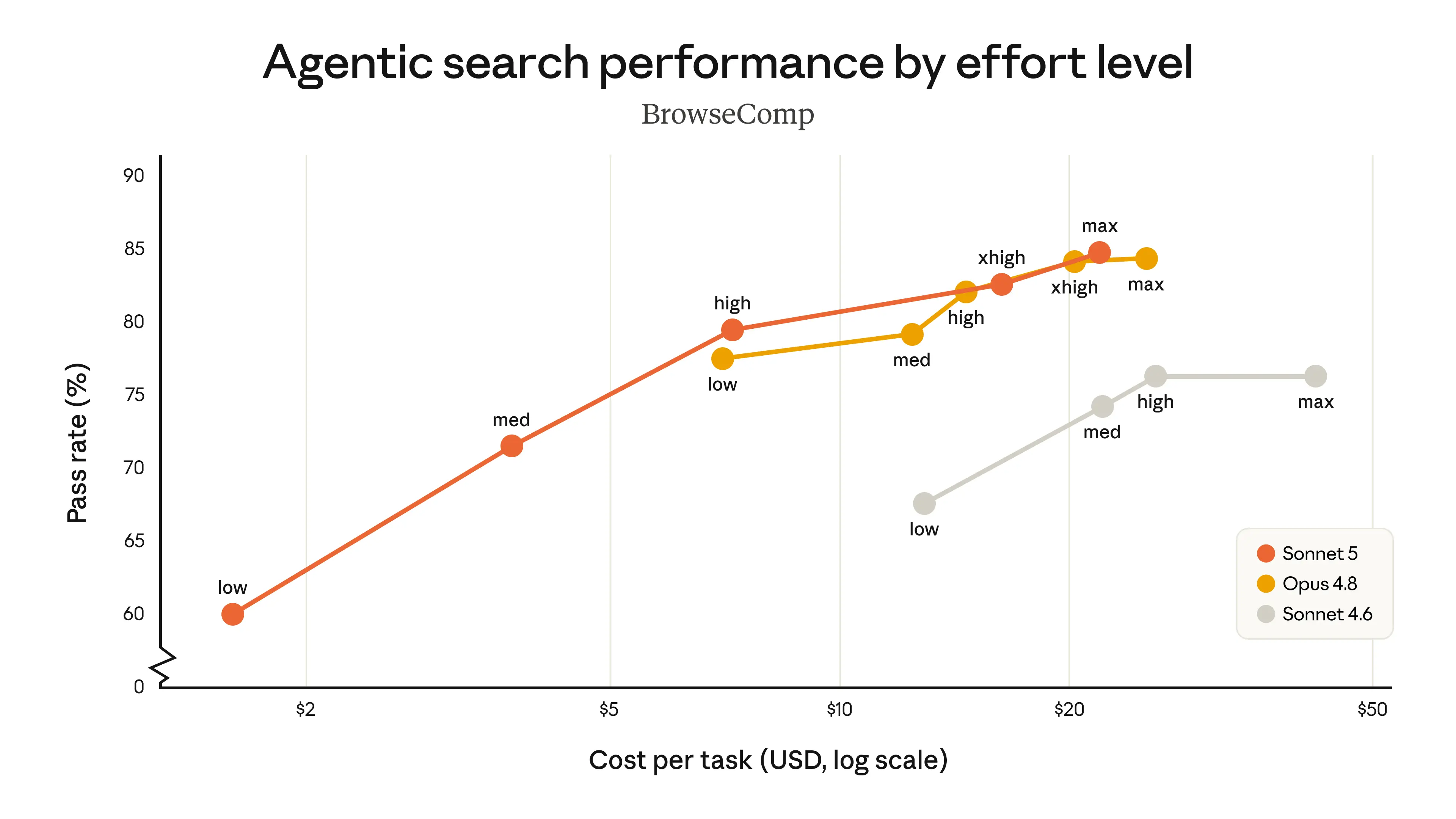
| Model | OSWorld-Verified | Agentic Depth | Cost (Input / Output per MTok) |
|---|---|---|---|
| Claude Sonnet 4.6 | 78.5% | Limited multi-step | Lower than Sonnet 5 |
| Claude Sonnet 5 | Matches Opus 4.8 at some settings | Full agentic loop | $2 / $10 (intro) · $3 / $15 (standard) |
| Claude Opus 4.8 | Highest | Strongest | Significantly higher |
Building an agentic product on Claude and want help picking the right model tier for each part of your pipeline? Naraway designs LLM architectures for startups and product teams.
See Our AI ServicesPricing: The Introductory Window
Anthropic is offering introductory pricing through August 31, 2026: $2 per million input tokens and $10 per million output tokens. After that, standard pricing applies at $3 input and $15 output. The introductory window is not just a discount: it is a signal to migrate and build now, before your cost models change. Teams already on Sonnet 4.6 who upgrade before September lock in a month of lower-cost exploration at significantly higher capability.
| Period | Input per million tokens | Output per million tokens |
|---|---|---|
| Until August 31, 2026 | $2 | $10 |
| September 1, 2026 onwards | $3 | $15 |
The model is the default on both Free and Pro plans on Claude.ai. API access uses the model identifier claude-sonnet-5. Enterprise, Team, Max, and Claude Code plans all have access.
What This Means Across Different Use Cases
The same underlying capability plays out differently depending on what you are building. Here is how Sonnet 5 changes the picture across a few common contexts:
For Software Teams
The self-verification loop and multi-step task completion are the two changes that matter most. An engineer in a startup running lean can now delegate entire debugging sessions to the model: write the test, find the root cause, implement the fix, run verification. The output does not just need review for correctness; it comes back already reviewed by the model. That removes one or two human-in-the-loop steps per task, compounding over a week of work.
For Operations and Business Teams
Teams automating CRM workflows, document processing, or multi-step client communications can now run those pipelines with far less scaffolding. Sonnet 5 does not stop when it hits a decision point that requires reading something: it reads it, decides, and continues. For operations teams in industries like insurance, legal services, or logistics, that end-to-end execution was previously only possible with Opus 4.8 and its associated cost.
For Founders Building AI Products
The cost-to-capability shift is the biggest unlock. If you were previously building on Sonnet 4.6 because Opus 4.8 was too expensive to serve at scale, Sonnet 5 moves the ceiling significantly. You get agentic depth at a price that scales with your product, not against it.
If you are a founder or product team evaluating Claude Sonnet 5 for production, Naraway can help you architect the right system from the start.
Talk to Us on WhatsAppSafety: Designed In, Not Added On
Anthropic's safety approach with Sonnet 5 deserves a clear reading. The model has a lower rate of undesirable behaviors than Sonnet 4.6, improves on refusing malicious requests, and is harder to manipulate through prompt injection from external content in the environment. On Firefox 147 exploit development, it achieved 0% success. That number is intentional: Anthropic designed Sonnet 5 to have substantially reduced cybersecurity offensive capability compared to Opus 4.8.
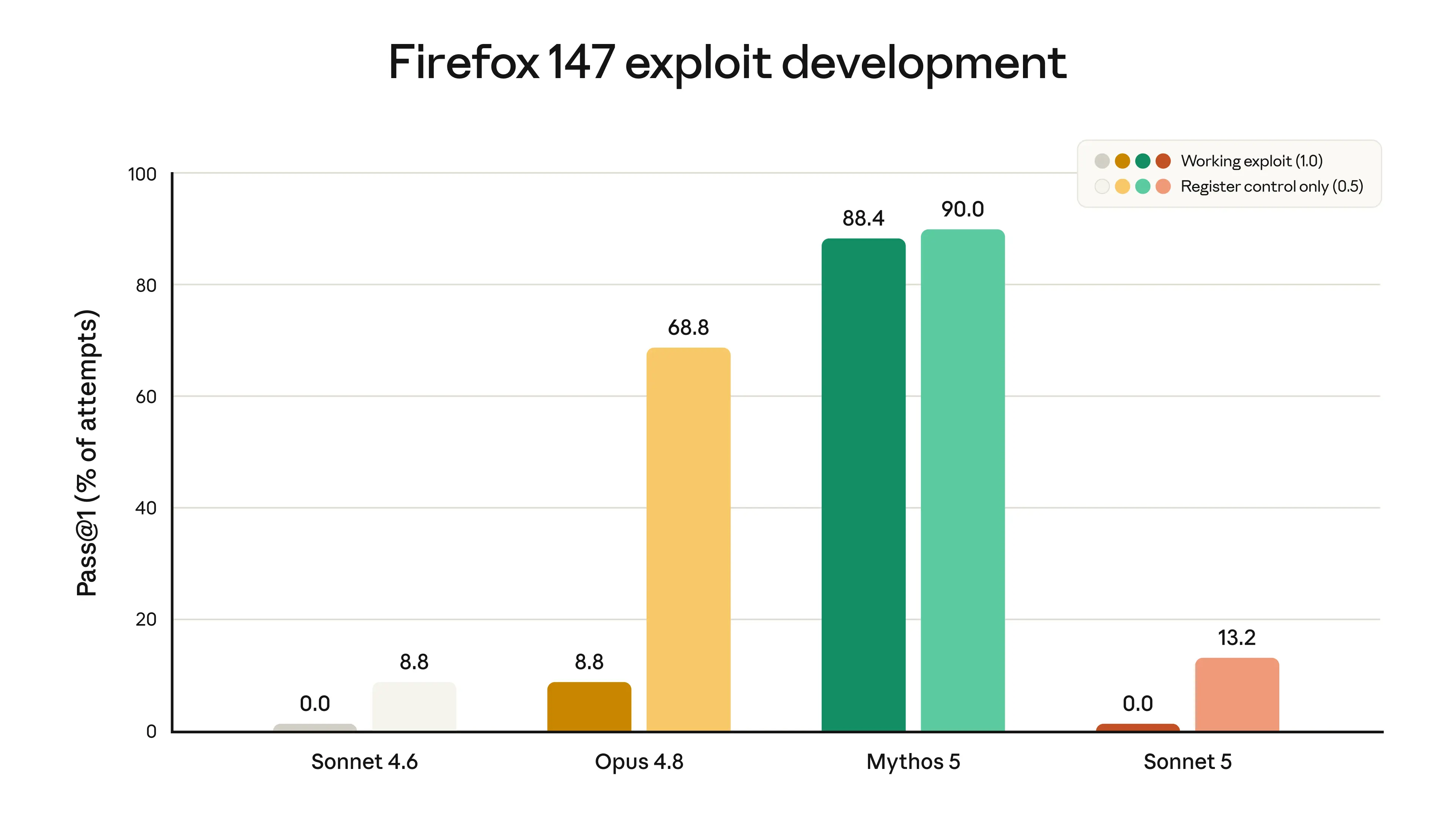
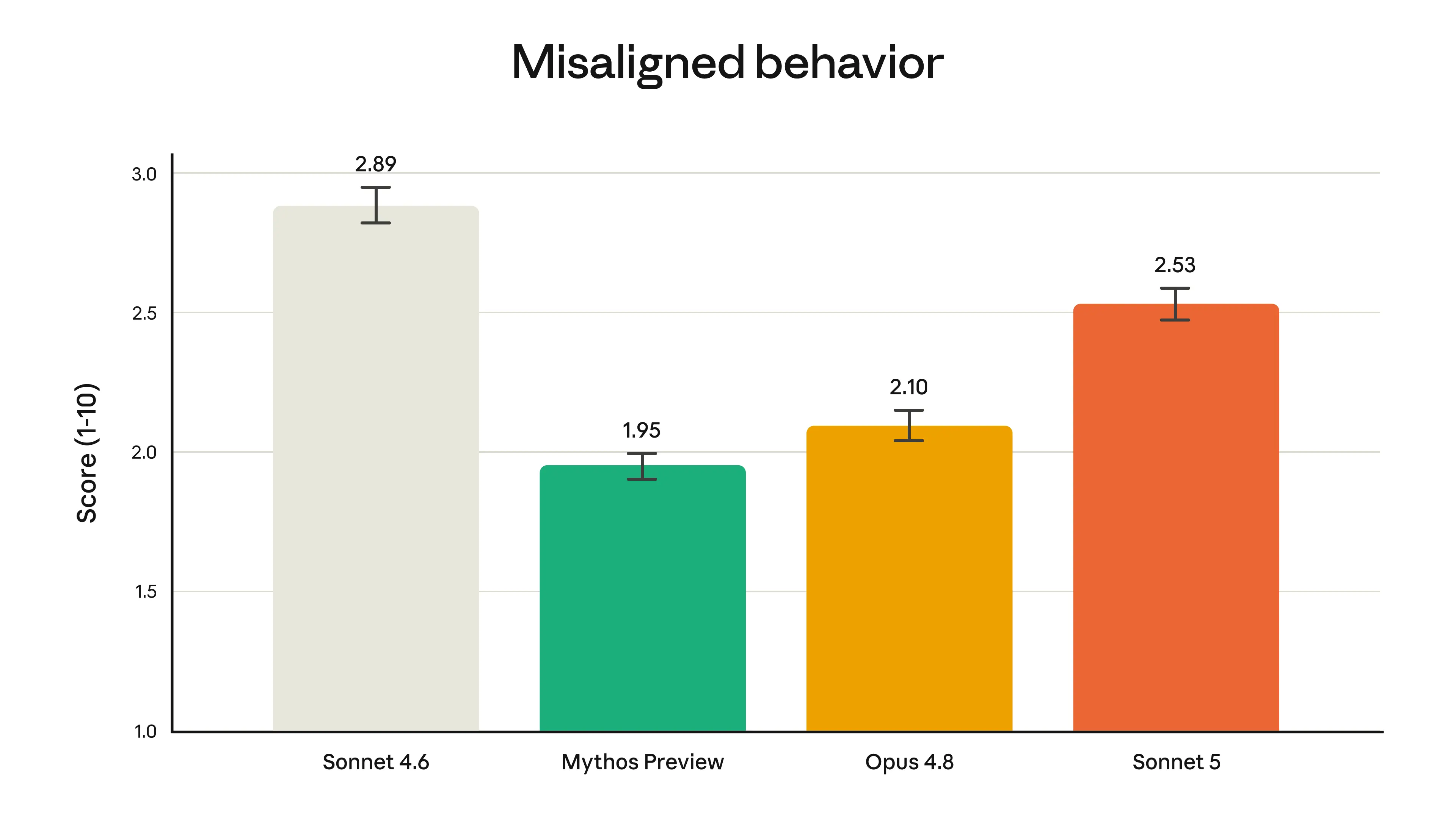
For teams deploying agentic systems in professional environments: finance, healthcare, legal, compliance, this is a feature, not a limitation. A model that completes complex multi-step tasks but is deliberately constrained from being weaponized is exactly what enterprise deployment requires. The safety profile is documented, testable, and consistent across API access.
The Tokenizer Change: Do Not Skip This
Sonnet 5 ships with a new tokenizer. The same content that worked within Sonnet 4.6's context window will require between 1.0 and 1.35 times more tokens in Sonnet 5. This is not a large number in isolation, but it matters in two places: prompts running near context limits, and cost projections for high-volume API usage.
Before migrating production applications from Sonnet 4.6, test your longest prompts against the new tokenizer. Recalculate your cost estimates using the new per-token pricing, and factor in the 15 to 35 percent token increase. Do this before August 31 so your numbers are accurate before the introductory pricing window closes.
Upgrade Checklist
- Switch the model ID in your API calls from the previous Sonnet identifier to
claude-sonnet-5 - Test your longest prompts: check for context limit issues under the new tokenizer
- Recalculate cost projections accounting for 15 to 35 percent higher token usage
- Audit your existing agentic scaffolding: Sonnet 5 handles more natively, so some prompt engineering you built for Sonnet 4.6 may now be redundant
- Take advantage of introductory pricing: complete your migration and benchmark before August 31
- For regulated environments: review Anthropic's system card for Sonnet 5's safety profile before production deployment
Need Help Migrating to Claude Sonnet 5?
Naraway builds and migrates AI-powered systems for product teams and enterprises. If you are moving from Sonnet 4.6 or evaluating Claude for the first time, we can scope the architecture, handle the integration, and ensure the tokenizer and cost changes do not catch you off guard.
Explore AI Integration